Introduction
Large Language Models (LLMs) have revolutionized the way we interact with technology, but their computational costs can quickly add up. For businesses and individuals alike, finding ways to optimize LLM usage is essential. This is where GPTCache comes in. By storing and reusing previously generated responses, GPTCache can significantly reduce the number of times an LLM needs to be called upon, resulting in substantial cost savings.
In this guide, we'll delve into the specifics of how GPTCache works, its benefits, and provide a step-by-step tutorial on implementing it. Whether you're a developer looking to optimize your application or a budget-conscious LLM user, this article will equip you with the knowledge to maximize your AI investment.
What is GPTCache and Why?
GPTCache is a versatile open-source tool designed to optimize the performance and cost-efficiency of GPT-based applications. By storing and efficiently retrieving previously generated LLM responses, GPTCache significantly reduces the need for repeated LLM calls. Users have granular control over cache behavior, including customization of embedding functions, similarity evaluation methods, storage location, and eviction policies. To enhance usability, GPTCache seamlessly integrates with popular platforms like OpenAI ChatGPT and Langchain.
- By storing previously generated LLM responses, GPTCache dramatically accelerates response times. When a similar query is encountered, the cached response can be retrieved instantly instead of requiring a new LLM call. This results in a noticeable performance boost for your application.
- Most LLM services charge users based on the number of API calls and the amount of processed text. By caching and reusing LLM responses, GPTCache can significantly reduce API call volume, leading to substantial cost savings. This is particularly beneficial for applications handling high traffic or frequent repetitive queries.
- GPTCache enhances the scalability of your application by mitigating the load on the LLM service. By caching frequently accessed responses, it prevents bottlenecks and ensures your application can handle increasing numbers of requests without compromising performance.
- Developing LLM applications can be costly due to the constant need for LLM API connections, even during the prototyping phase. GPTCache offers a solution by simulating LLM behavior with a local cache, significantly reducing development expenses. By storing pre-generated or mock LLM responses, GPTCache enables developers to test application features without relying on external APIs or network connectivity.
GPTCache leverages data locality by caching frequently accessed data, accelerating response times and reducing server load. Unlike traditional caching that relies on exact query matches, GPTCache employs semantic caching to identify and store semantically similar queries, significantly enhancing cache hit rates.
What is Semantic Cache? In essence, semantic caching is a powerful tool for enhancing application performance and reducing costs by storing and reusing the meaning of queries rather than just the raw data.
Unlike traditional caching that stores data based on exact matches, semantic caching focuses on the meaning of queries. By understanding the intent behind requests, it can significantly improve application performance and reduce server load.
Semantic caching achieves this by storing query representations, allowing for the retrieval of similar queries and their corresponding results. This not only speeds up response times but also optimizes resource utilization. Additionally, it can help handle complex queries that involve multiple data sources more efficiently.
By converting queries into numerical representations (embeddings) and utilizing a vector store for efficient similarity searches, GPTCache can intelligently retrieve relevant cached responses. This flexible approach allows users to customize the semantic cache components to fit specific use cases. While semantic caching can introduce potential inaccuracies, GPTCache provides performance metrics to aid in optimization and fine-tuning.
Sample Code - Exact Matching
import osimport openaiimport timefrom langchain_openai import OpenAIfrom langchain import PromptTemplate, LLMChainfrom gptcache.adapter.langchain_models import LangChainLLMsfrom gptcache import Cachefrom gptcache.processor.pre import get_promptopenai.api_key = os.getenv("OPENAI_API_KEY")template = """Question: {question}Answer: Let's think & respond step by step."""prompt = PromptTemplate(template=template, input_variables=["question"])llm = OpenAI()question = "How many cups did Pep Guardiola as a coach win and list them one by one?"llm_cache = Cache()llm_cache.init( pre_embedding_func=get_prompt,)before = time.time()cached_llm = LangChainLLMs(llm=llm)answer = cached_llm(prompt=question, cache_obj=llm_cache)print(answer)print(f"Time taken: {time.time() - before}")before = time.time()answer = cached_llm(prompt=question, cache_obj=llm_cache)print(answer)print("Cache Hit Time Spent =", time.time() - before)
Output:
Before Caching: Time taken: 4.301722049713135After Caching: Time taken: 0.0006661415100097656
Sample Code - Similarity Cache using GPTCache and Milvus vector database
- First question before Caching to ask LLM: "What did the president say about Justice Breyer?"
- Second similar question that hits the cache (avoid calling LLM): What was president's opinion about Justice Breyer?
import osimport openaiimport timefrom langchain import PromptTemplatefrom langchain.chains.question_answering import load_qa_chainfrom langchain_openai import OpenAIfrom gptcache import cachefrom gptcache.adapter.langchain_models import LangChainLLMsfrom gptcache.embedding import Onnxfrom gptcache.manager import CacheBase, VectorBase, get_data_managerfrom gptcache.similarity_evaluation.distance import SearchDistanceEvaluationfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.vectorstores import Milvusfrom langchain.document_loaders import TextLoaderopenai.api_key = os.getenv("OPENAI_API_KEY")template = """Question: {question}Answer: Let's think & respond step by step."""prompt = PromptTemplate(template=template, input_variables=["question"])question = "How many cups did Pep Guardiola as a coach win and list them one by one?"# get the content(only question) form the prompt to cachedef get_content_func(data, **_): return data.get("prompt").split("Question")[-1]onnx = Onnx()cache_base = CacheBase('sqlite')vector_base = VectorBase('milvus', host='127.0.0.1', port='19530', dimension=onnx.dimension, collection_name='cache_samples')data_manager = get_data_manager(cache_base, vector_base, onnx)cache.init( pre_embedding_func=get_content_func, embedding_func=onnx.to_embeddings, data_manager=data_manager, similarity_evaluation=SearchDistanceEvaluation(),)cache.set_openai_key()loader = TextLoader('state_of_union.txt')documents = loader.load()text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)docs = text_splitter.split_documents(documents)embeddings = OpenAIEmbeddings()vector_db = Milvus.from_documents( docs, embeddings, connection_args={"host": "127.0.0.1", "port": "19530"},)query = "What did the president say about Justice Breyer"docs = vector_db.similarity_search(query)llm = LangChainLLMs(llm=OpenAI(temperature=0))chain = load_qa_chain(llm=llm, chain_type="stuff")before = time.time()print(chain({"input_documents": docs, "question": query}, return_only_outputs=True))print(f"Time taken: {time.time() - before}")before = time.time()print(chain({"input_documents": docs, "question": "What was president's opinion about Justice Breyer"}, return_only_outputs=True))print(f"Time taken: {time.time() - before}")
Output:
{'output_text': " The president thanked Justice Breyer for his service and mentioned that he nominated Judge Ketanji Brown Jackson to continue Justice Breyer's legacy on the Supreme Court."}Time taken: 1.6161620616912842{'output_text': " The president thanked Justice Breyer for his service and mentioned that he nominated Judge Ketanji Brown Jackson to continue Justice Breyer's legacy on the Supreme Court."}After Caching: Time taken: 0.3508901596069336
Tailoring Your Semantic Cache
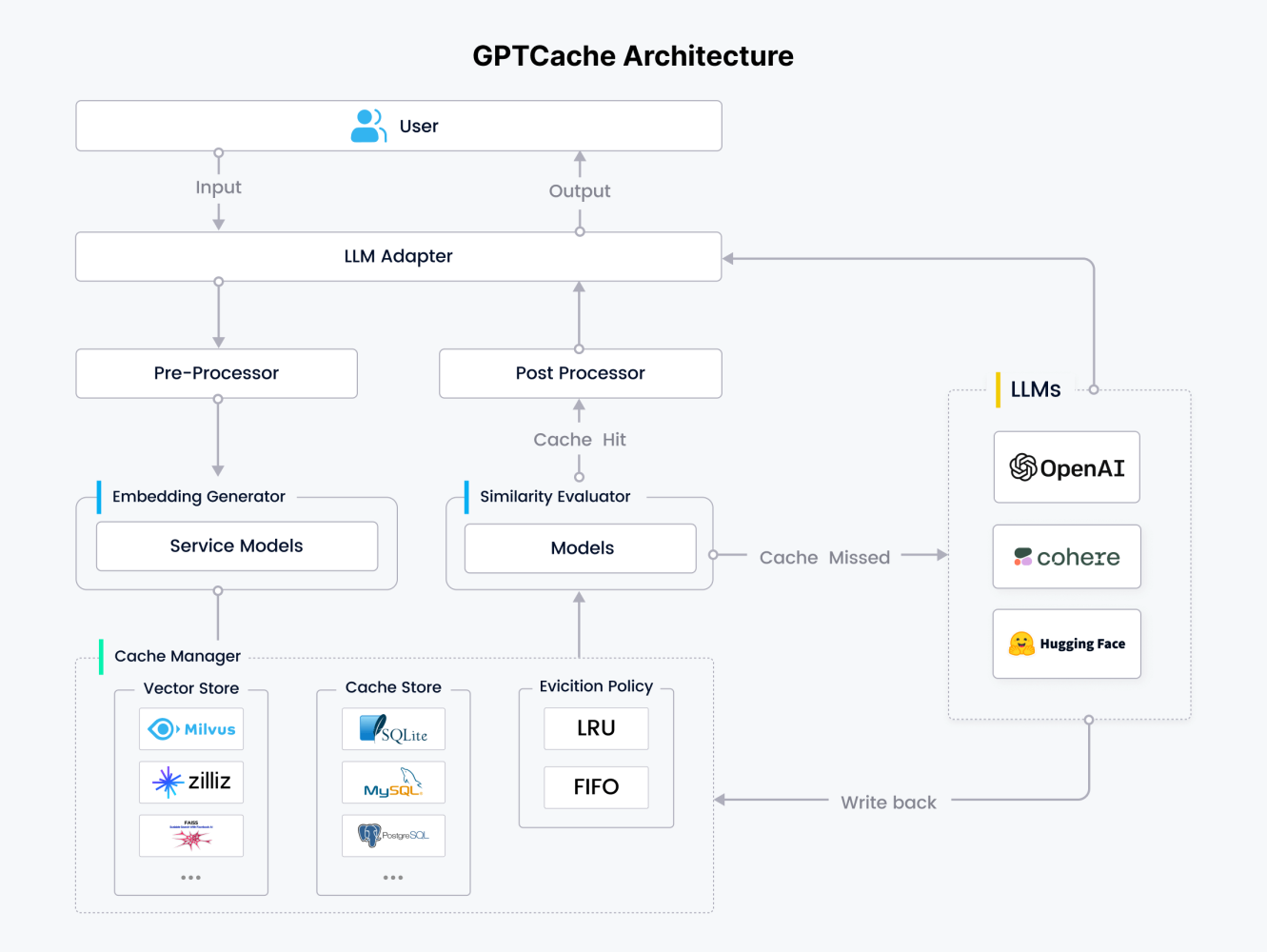
GPTCache is designed with flexibility in mind. Its modular architecture empowers users to tailor the semantic cache to their specific needs. By offering customizable components and options, GPTCache ensures that users can fine-tune the cache for optimal performance in their applications.
Preprocessor Optimization
The preprocessor enhances query efficiency by refining input data. This involves cleaning up redundant information, compressing content, truncating excessive text, and performing other optimization tasks to improve overall query performance.
LLM Adapter: Your Bridge to Diverse Language Models
The LLM Adapter serves as a universal interface for interacting with various language models. By standardizing API calls and request formats, it simplifies the process of experimenting with different LLM providers. With support for popular options like OpenAI, Langchain, and others, users can seamlessly switch between models without extensive code modifications. This flexibility accelerates development and testing while providing access to a wider range of LLM capabilities.
Embedding Generation
The Embedding Generator creates numerical representations (embeddings) of text data using a variety of supported models. These models include OpenAI, ONNX, Hugging Face, Cohere, fastText, Sentence Transformers, and image embedding models from Timm. The generated embeddings are then used to perform similarity searches within the cache.
Cache Store
The Cache Store is the repository for storing LLM-generated responses. These cached responses are crucial for efficient similarity comparisons and delivering matching results to users. GPTCache supports a wide range of popular databases, including SQLite, PostgreSQL, MySQL, MariaDB, SQL Server, and Oracle, allowing users to select the database that best aligns with their application's performance, scalability, and cost requirements.
Vector Store Integration
GPTCache offers robust vector store integration to facilitate efficient similarity searches. By calculating embeddings from incoming requests and identifying the K most similar entries, GPTCache accurately assesses request similarity. Users can choose from a variety of vector store options including Milvus, Zilliz Cloud, Milvus Lite, Hnswlib, PGVector, Chroma, DocArray, and FAISS to optimize performance and accuracy based on specific use case requirements. This flexibility ensures GPTCache can adapt to diverse application needs.
Cache Management and Eviction
GPTCache's Cache Manager oversees the operations of both the Cache Store and Vector Store. To maintain optimal cache performance, an eviction policy is implemented to remove outdated or less frequently used data when the cache reaches capacity. GPTCache currently supports the standard LRU (Least Recently Used) and FIFO (First In, First Out) eviction policies, allowing users to select the method that best suits their application's requirements.
Similarity Evaluator
The Similarity Evaluator determines the degree of resemblance between incoming requests and cached data. By analyzing information from the Cache Store and Vector Store, it employs various strategies to calculate similarity scores. These scores are crucial for deciding whether to serve a cached response or generate a new one. GPTCache provides a flexible framework for integrating different similarity algorithms, allowing users to tailor the evaluation process to specific use cases and optimize performance.
Post-Processor
The Post-processor is responsible for preparing the final response that is delivered to the user. When a suitable cache hit is identified, it formats and delivers the cached response. In cases where a cache miss occurs, the Post-processor coordinates with the LLM Adapter to request a response from the underlying LLM, and subsequently stores the new response within the Cache Manager.
Summary
GPTCache is an open-source library that significantly reduces LLM costs and improves application performance by caching and reusing LLM responses. It offers a modular architecture allowing users to customize the cache for specific needs. Key components include a preprocessor for query optimization, an LLM adapter for model integration, an embedding generator for similarity calculations, a cache store for response storage, a vector store for efficient search, a similarity evaluator for matching requests, an eviction policy for cache management, and a post-processor for delivering responses. By leveraging semantic caching, GPTCache goes beyond traditional caching methods to achieve higher efficiency and accuracy.